Creating End-to-End MLOps pipelines using Azure ML and Azure Pipelines
In this 7-part series of posts we’ll be creating a minimal, repeatable MLOps Pipeline using Azure ML and Azure Pipelines.
The git repository that accompanies these posts can be found here.
In this series we’ll be covering:
- Part 1 – Introduction
- Part 2 – Resource Set Up
- Part 3 – Data Pipeline
- Part 4 – Environment Pipeline
- Part 5 – Model Training Pipeline
- Part 6 – Model Deployment Pipeline
- Part 7 – Continuous Integration (CI) Pipeline
Quick disclaimer: At the time of writing, I am currently a Microsoft Employee
Part 1 – Introduction
In this post we will cover:
- Who is this tutorial for?
- What is MLOps?
- Why Azure Pipelines?
- Why Azure Machine Learning?
This series of posts will assume the reader has some knowledge & experience of data science workflows.
Who is this tutorial for?
This tutorial is for data science practitioners/enthusiasts or data engineers, that would like to set up a minimal, robust, repeatable set of pipelines for productionising Machine Learning models in the cloud using Microsoft Azure.
There are lots of other resources that can help you learn Azure Machine Learning, from the basics through to the more complex nuances, not least the official Microsoft documentation. It is a very powerful tool and one I would recommend to any data scientist. However it can sometimes be a little overwhelming to know how to put everything together in your own production environment.
In this series of posts, we’ll help you set up pipelines from scratch that will allow us to extract and transform data, set up an environment, train and deploy machine learning models.
What is MLOps?
MLOps is the enablement of the automated management of the end-to-end machine learning lifecycle.
It helps data engineers, developers and data scientists work collaboratively to productionise machine learning models. It’s no use having an ML model that performs super well and could save a huge amount of money if it never goes into production and remains in pickle files or jupyter notebooks.
Also, once it’s in production, it won’t change with the times. As time progresses, the underlying data used to train the model becomes stale and the performance of the model drifts. We need to have a way of updating our production services with models trained on up-to-date data.
In this 7-part series of posts we’ll set up pipelines to create a minimal end-to-end MLOps pipelines to achieve the following using Azure Machine Learning and Azure Pipelines:
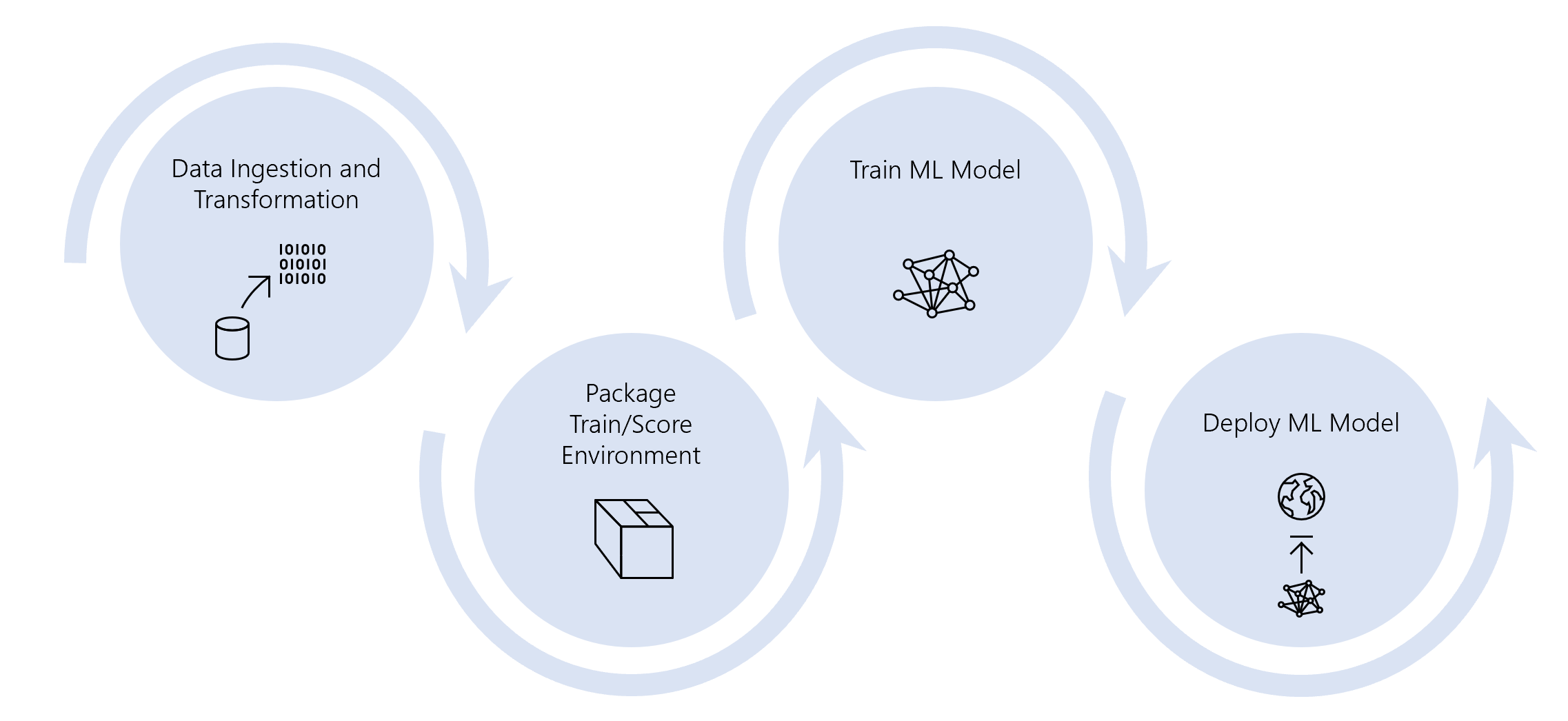
Across this series of posts, we will create 5 Azure Pipelines in this example project.
Each of these pipelines are on an automated trigger – triggered either by a change to code or on a schedule. However, if we make changes and want to trigger the pipelines manually, we can do so through Azure Pipelines.
The pipelines are as follows:
Data Pipeline
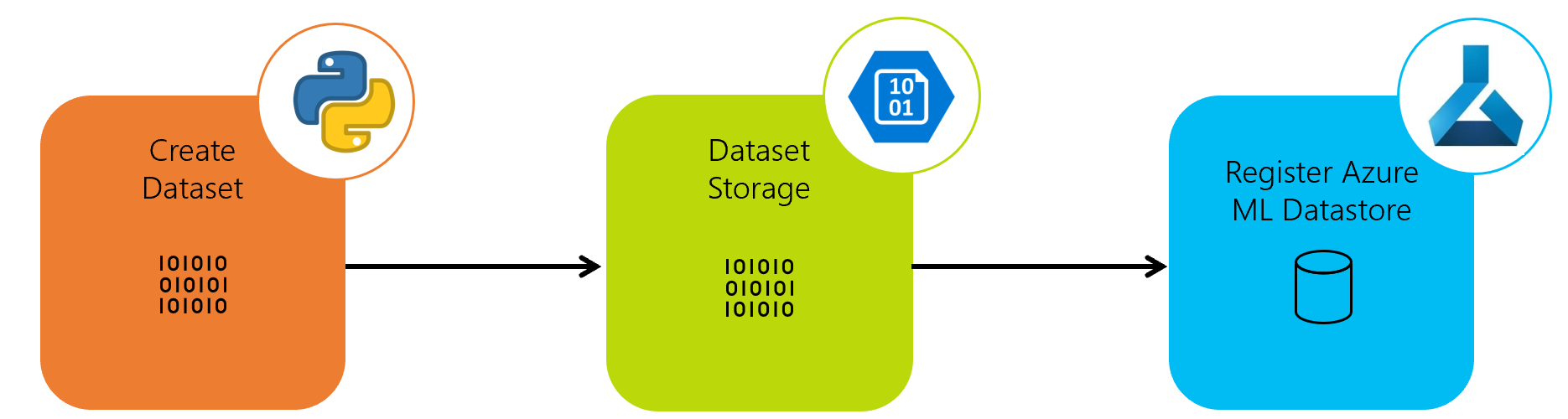
First we’ll have a data Pipeline to create a dataset and upload it to Azure Blob Storage. This datastore will then be registered with Azure Machine Learning ready for using in our model training pipeline.
We’ll set this up as a daily pipeline.
Environment Pipeline
Second, we’ll create an Azure ML Environment using a custom python package. The custom python package we’ll use is in our Azure Repos git repository.
Often we’ll have one or more internal packages that will be used for sharing code for repeatable tasks such as custom data transformation we’d like to share across model training and model scoring.
We also install any external packages we need into this environment.
We’ll want to use this python package in our model training and model deployment, so each time we merge our code into our master branch, we’ll update the Azure ML Environment with our custom python package.

Model Training Pipeline
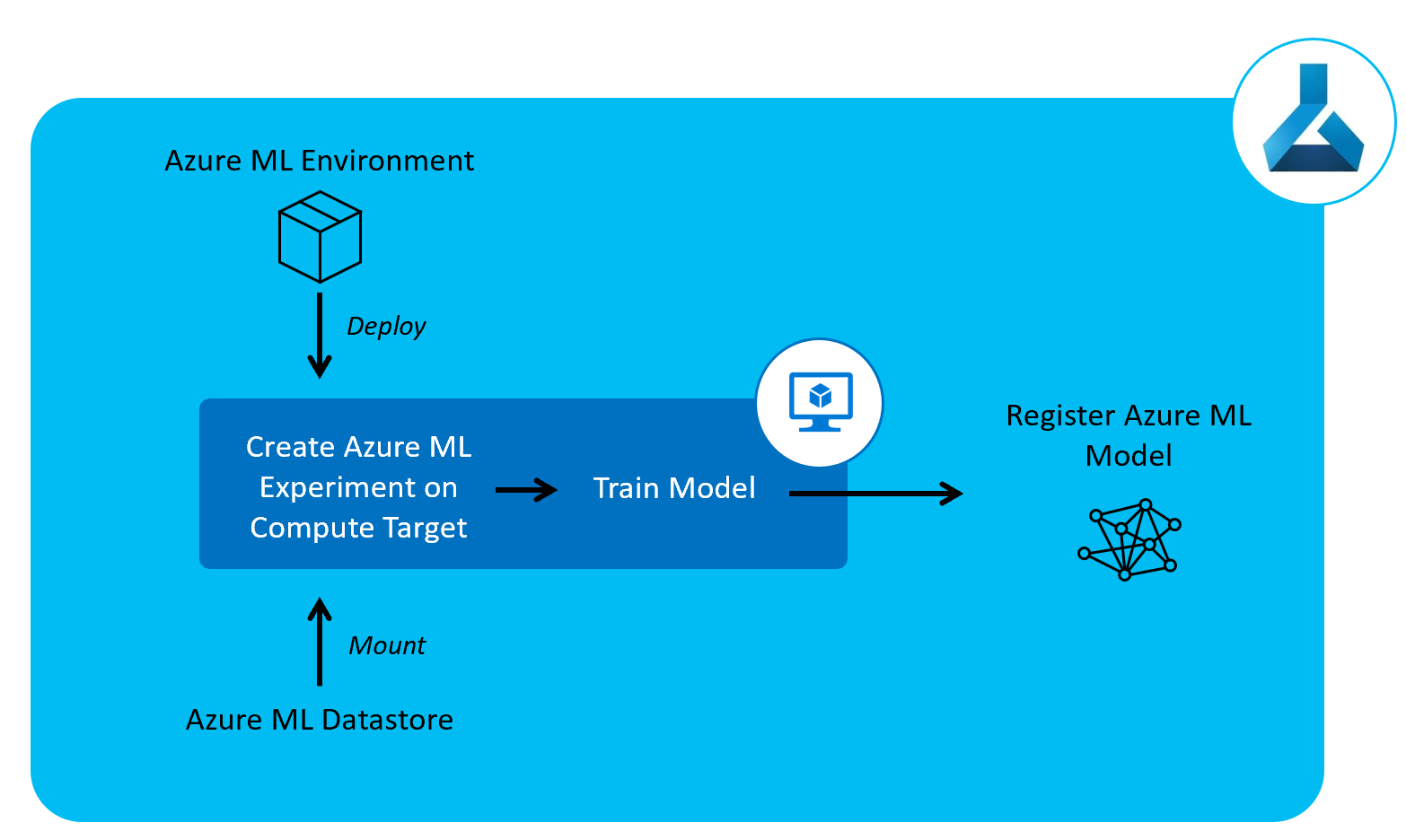
The third pipeline we’ll create is a model training Pipeline to train our ML model and register it to Azure ML Models.
In this pipeline we set up the compute node we’ll be using for training and, on this compute node, we pull in the environment we set up in the previous pipeline. We also mount the datastore we registered in our data pipeline for training our model.
We’ll have this pipeline on a schedule to retrain the model once per week.
Model Deployment Pipeline
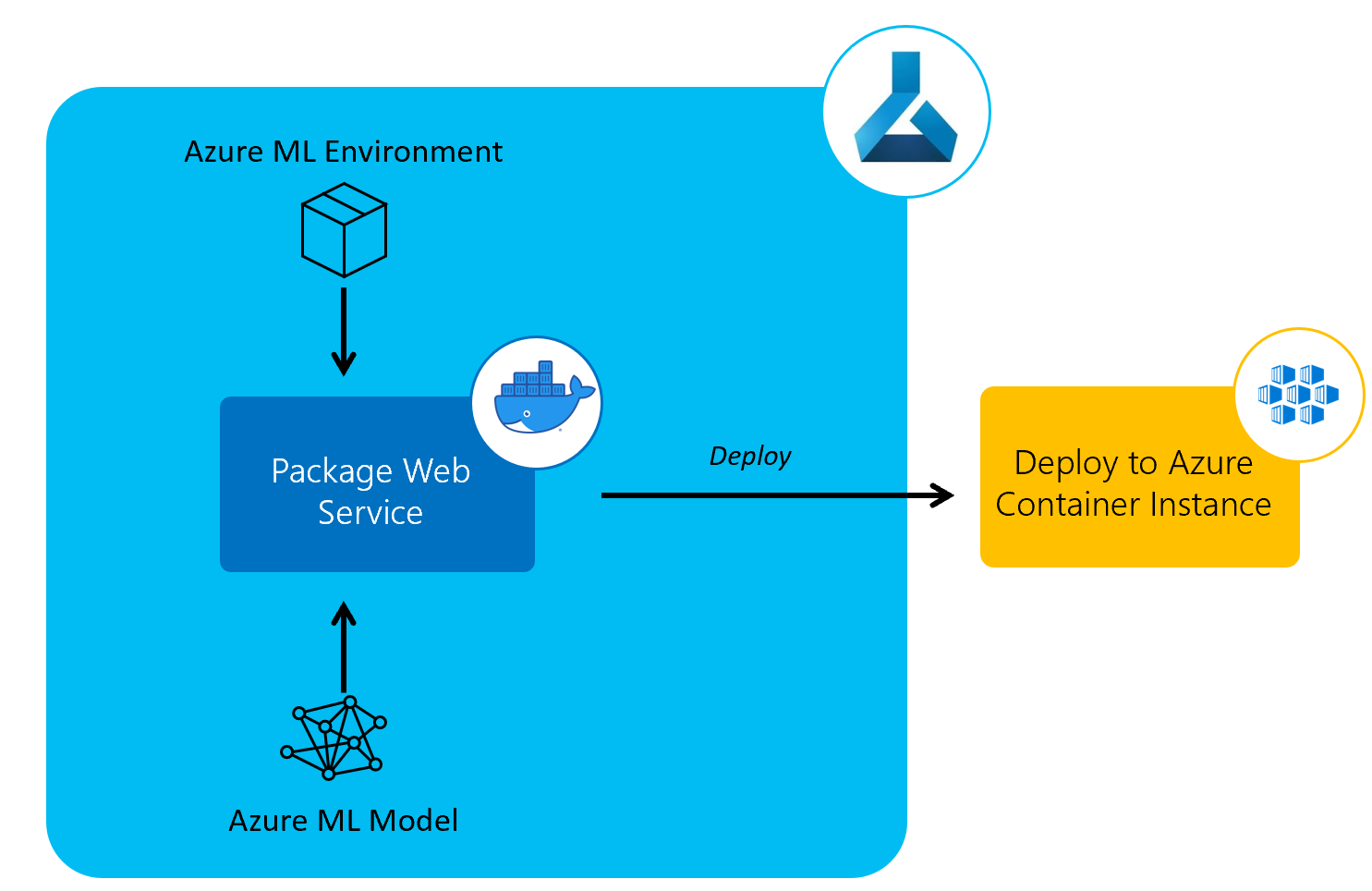
Once we’ve got a trained, registered model, we’ll have a Model Deployment Pipeline to deploy the trained models to a web service using Azure Container Instances.
We will also run this once a week once our model training/retraining pipeline is complete.
CI Pipeline
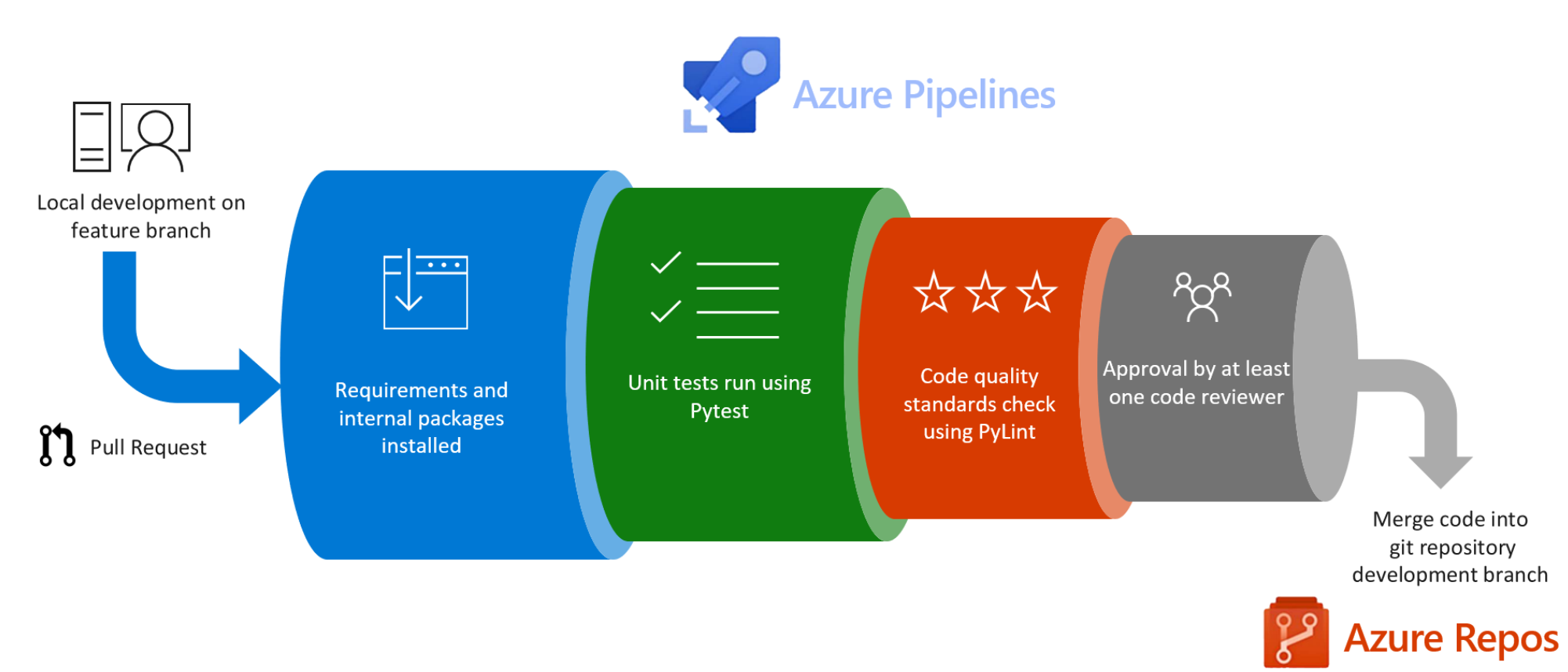
The other pipelines are focused on the tasks that you’ll probably be more interested in as a data scientist. However, it’s important to note that you’ll often be working on code with others and this will be production code – so it’s important to enforce a set of coding standards and a suite of unit tests to run.
In our CI pipeline, every time a user makes a pull request in git, we’ll be running pylint for static code analysis and for automated running of tests. We’ll publish the test results and code coverage back to Azure DevOps for users to view before choosing to merge the code.
The following CI pipeline is the one I often use:
Why Azure Pipelines?

We’ll be using Azure Pipelines in this example to set up and trigger pipelines.
Azure Pipelines are cloud-hosted pipelines that are fully integrated with Azure DevOps. You can either use a yaml file or a UI-based tool in Azure DevOps to set up your pipelines.
They can be used with code stored in a range of repository locations, including Azure Repos and Github.
I’m personally a fan of Infrastructure as Code (IaC) so we’ll be using the yaml definitions of pipelines. As taken straight from the zen of python – “Explicit is better than implicit” – and I think you should only have to look at your code to know what will be deployed and run during these pipelines.
Azure Pipelines include a huge range of functions for running pipelines for tasks such as testing, static code analysis, building, deploying etc.
As an alternative, we could use Azure Data Factory, which includes a full assortment of integrated ETL tools, to manage the pipelines but as we won’t need any of this additional functionality and to keep resources to a minimum we’ll stick to Azure Pipelines.
Why Azure Machine Learning?

Azure Machine Learning provides a whole host of functionality to accelerate the end-to-end machine learning lifecycle to help deploy enterprise-ready ML solutions quickly and robustly.
We’ll be using Azure Machine Learning for a range of tasks concerning the management of the ML lifecycle including:
- Registration of data sources and mounting of data storage to training environment
- Storage and versioning of the environment in which to execute training and scoring
- Managing compute for training experiments
- Tracking training experiment runs and associated metrics
- Storage and versioning of trained ML models
- Deployment of models to a web service using Azure Container Instances (Azure Kuberenetes Service also available)
Let’s begin with setting up the resources we’ll need.